18 架构:需求分析 (下) · 实战案例
你好,我是七牛云许式伟。
今天,我们继续上一讲关于架构第一步 “需求分析” 的讨论。为了能够获得更加具体的观感,我们选了两个实战的案例,如下:
- 打造 “互联网”;
- 存储新兵 “对象存储”。
案例: 打造 “互联网”
从对信息科技的影响面来说,最为标志性的两个事件,一个是计算机的诞生,另一个是互联网的诞生。
我们前面在 “[05 | 思考题解读: 如何实现可自我迭代的计算机?]”这一讲中,已经剖析过一个 MVP 版本的计算机是什么样的。
今天,我们就以 “互联网” 这个产品为题,看看应该怎么去做需求分析。
我们想象一下,把我们自己置身于互联网诞生之前。互联网并不是第一张网。在此之前的信息世界中,更多的是某个企业专用的局域网。不同的企业会选择不同公司所提供的网络方案。这些网络方案缺乏统一的规划,彼此并不兼容。
那么,怎么才能打造一个连接人与人、企业与企业,甚至是物与物,能够 “连接一切” 的 “互联网”?
首先,从根源需求来说,我们期望这不是某个巨头公司的网,也不是政府的网。这是需求的原点,这一点上的不同,产生的结果可能就很不一样。
如果我们忽略这一点,就有可能会把它做成微信网(WechatNet),或者中国网(ChinaNet)。它们可能会是一张巨大的网,但都不是 “互联网”。
所谓 “互联网” 首先应该是一张开放的网。它应该可以让很多国家很多公司参与其中,形成合力。它不应该存在 “造物主”,一个可以在这张网络中主宰一切的人。
开放,最基础的层次来说,意味着需要定义网络协议标准,尤其是跨网的数据交换标准。这里的跨网,指的是跨不同的网络设备,不同的网络运营商。
开放,从另一个角度来说,是对应用程序软件的开放。想要 “互联网” 真正能够连接一切,只是把物理的网络连接在一起是不够的,还要有能够丰富的 “连接一切” 的应用。
为了能够让更多应用可以更便捷地连接网络,我们需要提供方便应用接入的高层协议。这个协议需要屏蔽掉网络连接的复杂性(丢包重传等)。
但这还不够。“互联网” 这样的基础设施,启动阶段没有应用去吸引用户是不行的。所以我们需要 “吃自己的狗粮”,开发若干互联网应用的典型代表。
有一些需求可能非常非常重要,但是我们需要阶段性放弃,例如安全。加密传输并没有作为互联网的内建特性,这极大降低了互联网的实施难度。
从另一个角度考虑,为什么不把安全放在最底层,也要考虑方案的可持续性。一个安全方案是否能够长期有效,这非常存疑。
但是物理网络一旦存在,就很难做出改变(想想我们从 IPv4 过渡到 IPv6 需要多少年吧)。所以从这个角度来说,我们也不希望安全是一个网络的底层设施。
这并不意味着安全问题可以不解决,只是把这事儿留给了软件层,留给操作系统和应用程序。这是一个极其明智的选择。相比物理网络而言,软件层更加能够经受得起变更。
总结来说,要想把 “互联网” 这个项目做成,需要考虑这样一些事情。
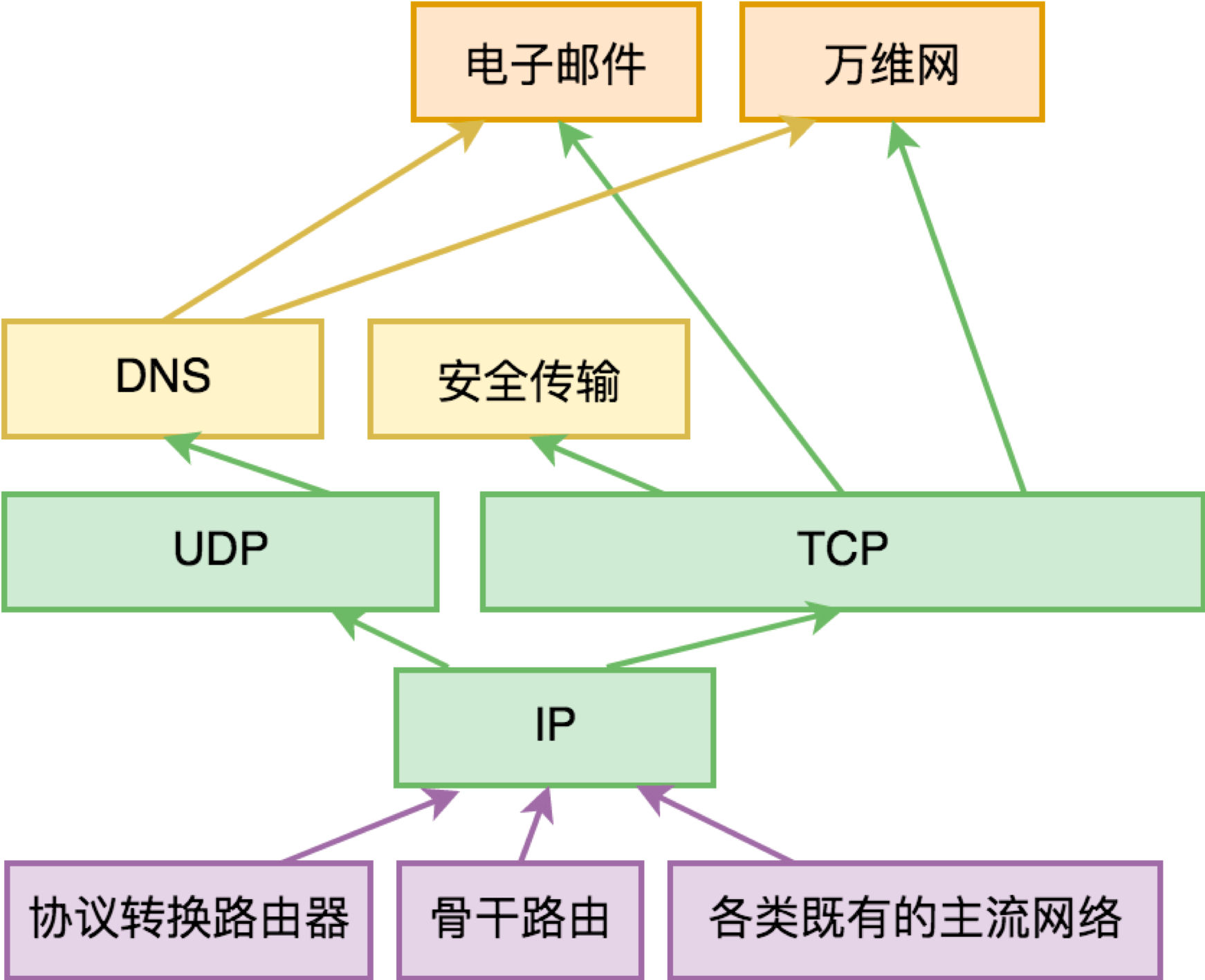
- 一个能够连接所有既有网络的协议标准,我们不妨叫它互联网协议(Internet Protocol),简称 IP 协议。
- 一张连接城市的骨干网络,至少有两个城市互联的试点。
- 打通骨干网络和主流企业专用网络的路由器。
- 一套方便应用开发的高阶网络协议,工作在 IP 协议之上。
- 一份支撑互联网应用程序的基础网络协议栈源代码或包(package),方便主流操作系统厂商、网络设备厂商集成。
- 若干典型互联网应用,如电子邮件(Email)、万维网(WWW)等。
- 一份安全传输的网络协议方案(远期),及其源代码或包(package)。
让我们先来看下物理网络的构建。
首先,构建骨干网络。不同城市可以由若干个骨干网路由器相连。骨干路由器可以看做是由一个负责路由算法的计算机,和若干网络端口构成,如下图所示。
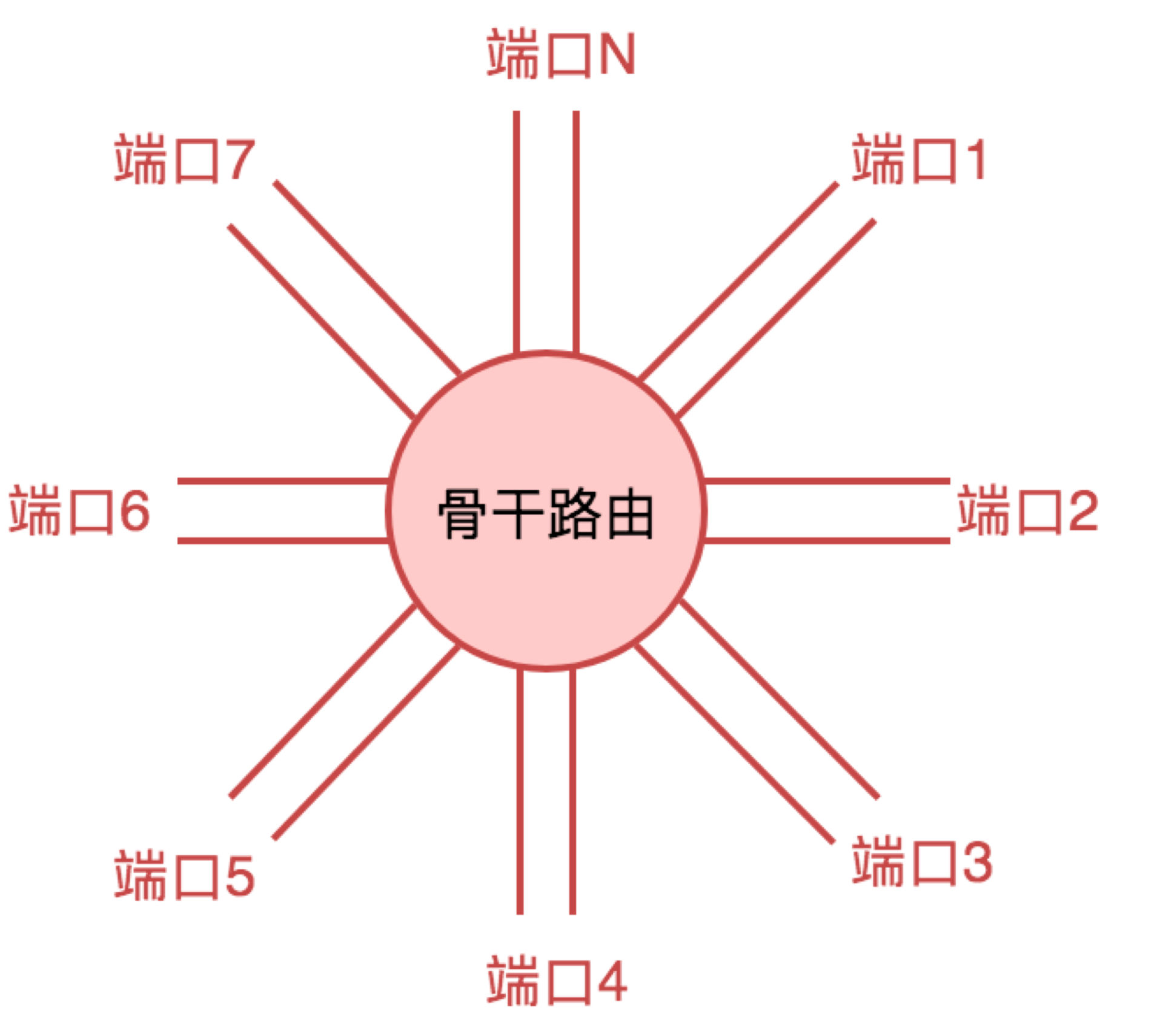
每个端口可能和其他城市相连,也可能和该城市内的某些大型局域网相连。一个局域网和城际网络从抽象视角看,没有非常本质的不同,只不过是采用的网络技术有异,使用的网络协议有异。
一个局域网可以简化理解为由若干台交换机连接所有的计算机设备。而交换机同样也可以看做是由一个负责路由算法的计算机,和若干网络端口构成,如下图所示:
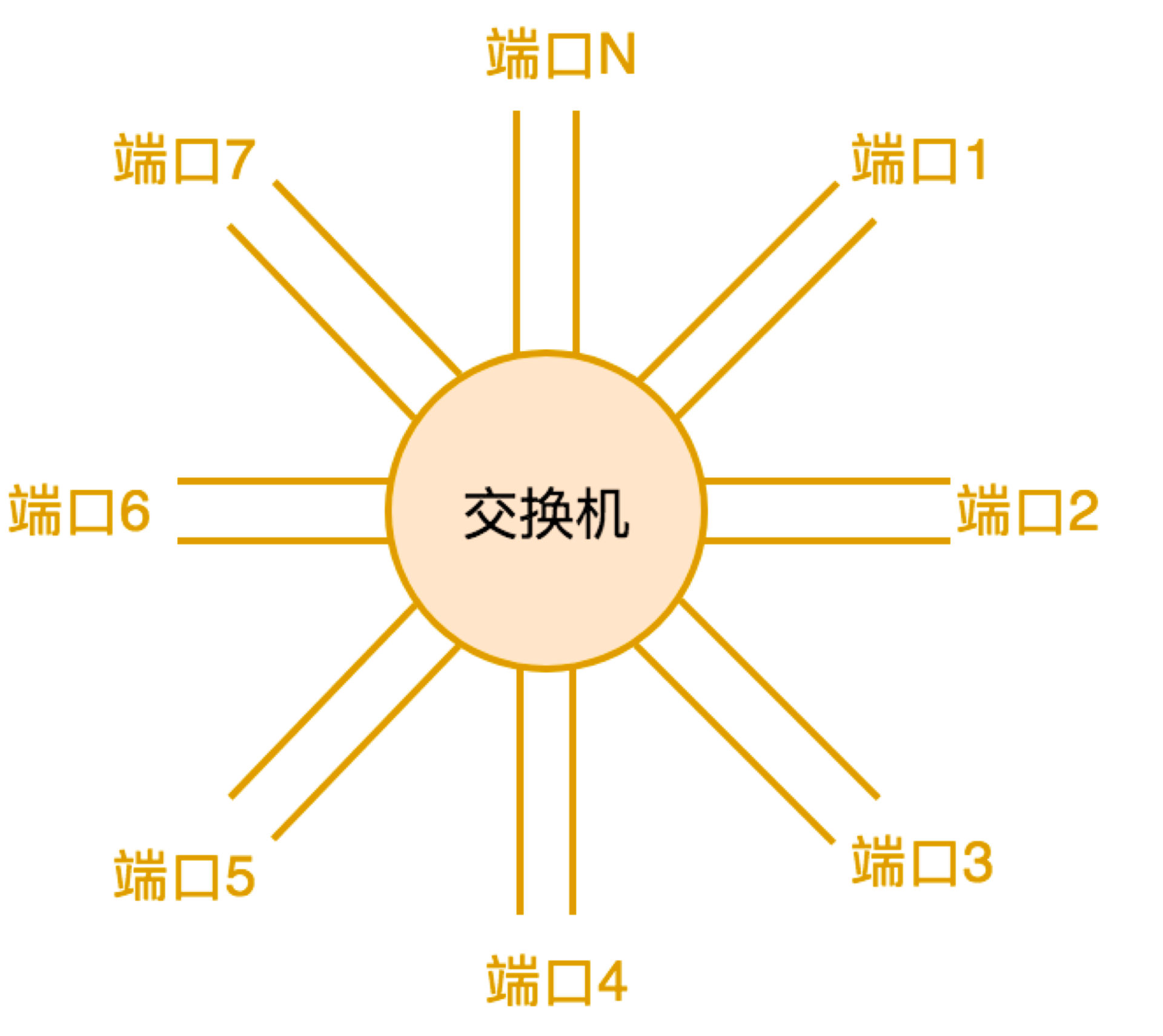
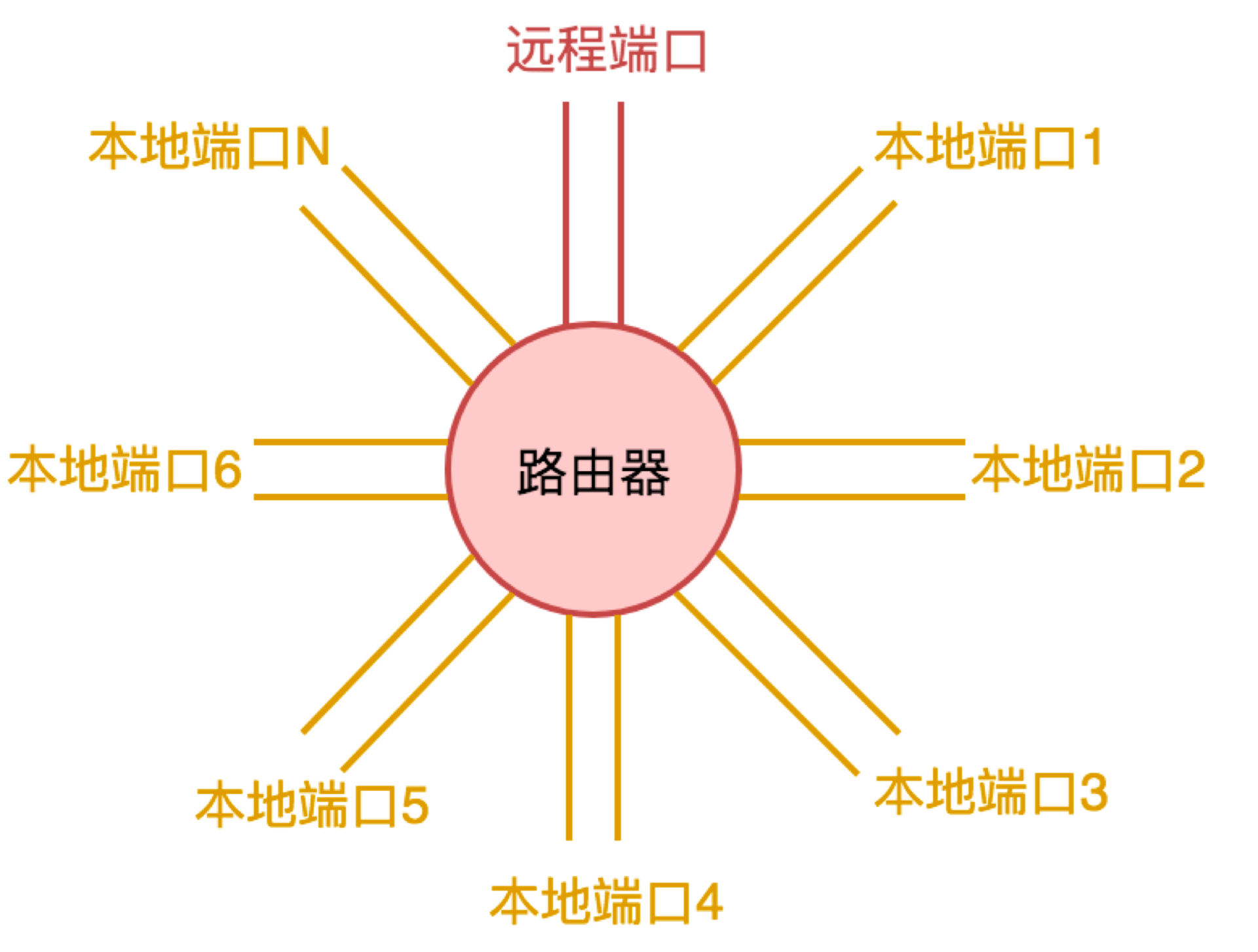
剩下的问题是怎么对接骨干网络和局域网。这需要有人负责进行网络协议转换,它就是路由器。一台路由器上有两类端口,一类端口为本地端口,连接局域网内的设备,比如交换机,或者直接连普通的计算机。另一类端口为远程端口,负责接入互联网。
理清楚了物理网络后,我们再来看应用构建。我们打算打造两个杀手级应用(Killer Application):电子邮件(Email)和万维网(WWW)。
在考虑应用的用户交互体验时,我们发现,物理网络能够处理的 IP 地址,和人类方便记忆的地址非常不同,故而我们决定引入域名(domain)作为人与人交流用途的地址。为此,我们引入了 DNS 地址簿协议,用于将域名解析为物理网络可理解的 IP 地址。
综上分析,最终我们得到 MVP 版本的 Internet 项目的各子系统如下:
案例: 存储新兵 “对象存储”
对象存储是非常新兴的一种存储系统。是什么样的需求满足方式的变化,导致人们要创造一种新的存储呢?
对象存储是伴随互联网的兴起,尤其是移动互联网的兴起而产生的。
首先,互联网应用兴起,软件不再是单机软件,用户在使用应用软件的过程中产生的数据,并不是跟随设备,而是跟随账号。 这样,用户可以随心所欲地切换设备,不必考虑数据要在设备间倒来倒去的问题。
数据跟随账号,这是互联网应用的第一大特征,区别于单机软件的关键所在。
其次,用户交互方式的变化。 用户不再打字用纯文本沟通,而是用照片、视频、语音等多媒体内容来表达自己的想法。
移动化加剧了这一趋势,在手机上打字是非常痛苦的事情。拍拍照、拍拍视频、说说话(语音输入)更加符合人的天性,尤其是手机用户覆盖面越来越宽,大部分用户属于没有经过专业培训的普通用户,这些手段是最低准入门槛的交互方式。
最后,用户体验诉求的提升。 计算机显示器早年是黑白的,后来有了256色,有了真彩色(TrueColor);显示器的屏幕分辨率,也从320x240,到640x480,到今天我们再也不关心具体分辨率是多大。随之发生变化的,是一张照片从100K,到几兆,到几十兆。
这些趋势,对存储系统带来的挑战是什么?
其一,规模。 那么多用户的数据,一台机器显然放不下了,要很多很多台机器一起来保存。
其二,可靠。 用户单机对存储的要求并不高,机器硬盘出问题了,不会想着找操作系统厂商或者软件应用厂商去投诉。但是,用户数据在服务端,数据丢了那就是软件厂商的责任,要投诉。
其三,成本。 从软件厂商来说,那么多的用户数据,怎么做才能让成本更低一些。
其四,并发吞吐能力。 大量的用户同时操作,有读有写,怎么保证系统是高效的。
另外,从存储系统的操作接口来说,我们分为关系型存储(数据库,结构化数据)和文件型存储(非结构化数据)。我们今天的关注点在文件型存储上。
对于文件型存储来说,相关的备选解决方案有很多,我们简单罗列如下。
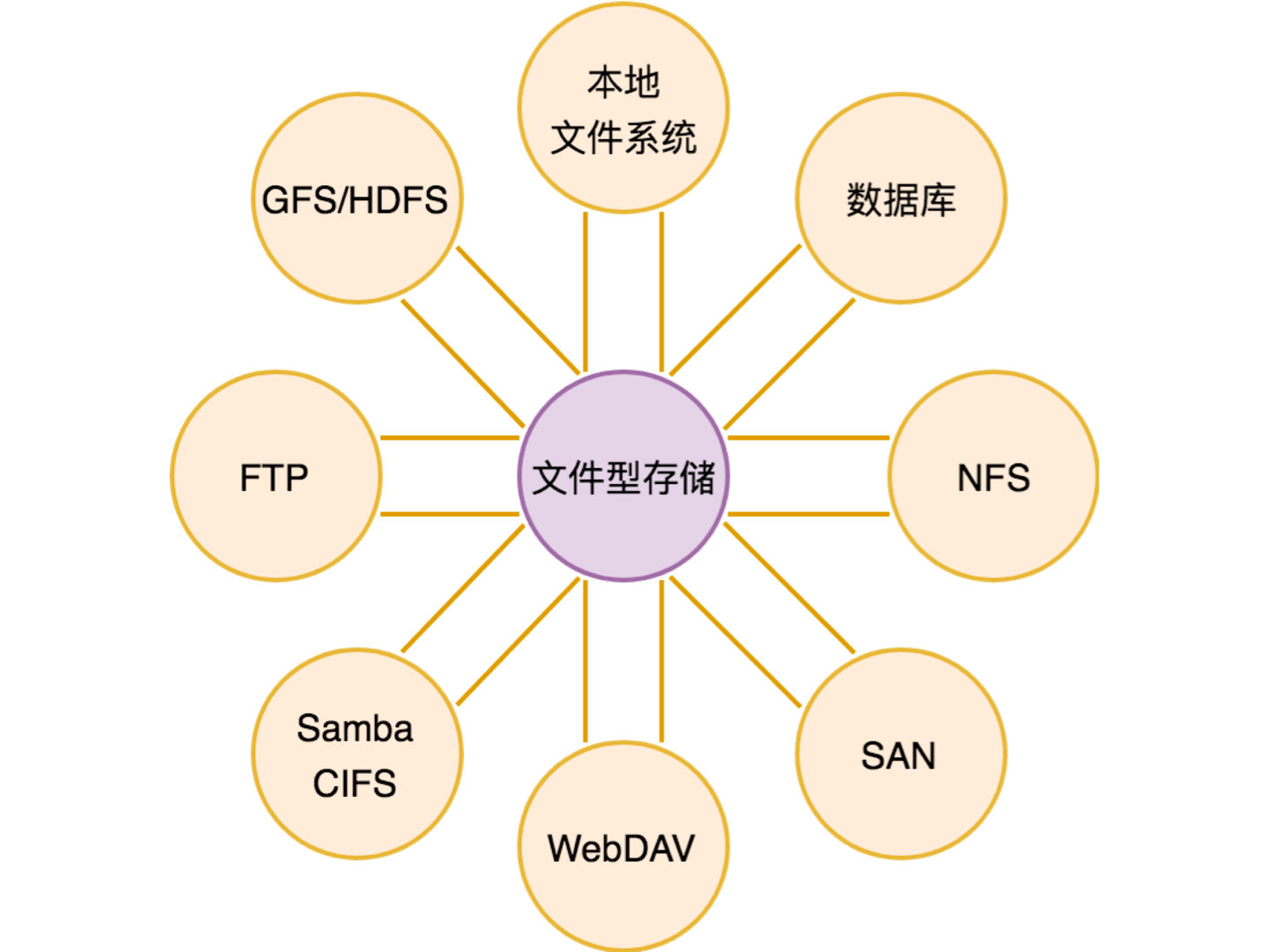
第二类是网络文件系统,可以统称为 NAS,如上面的 NFS、FTP、Samba(CIFS)、WebDAV,都只是 NAS 存储不同的访问接口。
第三类是数据库,它通常用于存储结构化数据,比较少作为文件型存储。但也有人在这么做,如果单个文件太大,会切成多个块放到多行。
第四类是 SAN,它是块存储。块存储和关系型存储、文件型存储都不同,它模拟的是硬盘,是非常底层的存储接口。很少会有应用直接基于块存储,更多的是 mount 到虚拟机或物理机上,然后供应用软件需要的存储系统使用。
第五类是分布式文件系统 GFS/HDFS。GFS 最早是为搜索引擎网页库的存储而设计,通常单个文件比较大,非常适合用于日志类数据的存储。这也是为什么 Hadoop最后从大数据领域跑出来,原因就是因为大数据处理的就是日志。
你可以看到,除了数据库和 SAN,我们不用细分析就知道它们不是文件型存储的最佳选择,其他几类包括本地文件系统、NAS、GFS/HDFS 有一个共同特征,就是它们的使用接口都是文件系统(FileSystem)。
那么,我们就来看下文件系统(FileSystem)对于大规模的文件型存储来说有什么问题。
最大的问题是,文件系统是一棵树(Tree)。除了对单个文件的操作只需要锁住该文件外,所有对树节点的修改操作,比如把 A 节点移到 B 处,都是一次事务操作,需要锁住整棵树。
这对规模和并发吞吐能力都是伤害。从规模来说,分布式事务是很难的(这也是为什么分布式数据库很难做的原因),做出来性能也往往好不到哪里去。从并发吞吐能力来说,如果系统存在大锁,即在锁里面执行费时的操作,就会大幅降低系统的并发吞吐能力。
传统的 NAS 出现比较早,所以它没有考虑“大规模条件下存储会有什么样的挑战”是非常正常的。
GFS/HDFS 为什么没有考虑大规模问题?这是 Google 设计 GFS 的背景导致的,网页库存储,或者日志型存储的共同特征是单个文件很大,可以到几个 G 级别,这样的话文件系统的元数据就会减少到单台机器就可以存储的级别。
所以对象存储出现了。它打破了文件型存储访问接口一定是文件系统(FileSystem)的惯例。它用的是键值存储(Key-Value Storage)。
从使用接口来说,首先选择文件所在的桶(Bucket),它类似于数据库的表(Table),只是一个逻辑划分的手段;然后选择文件的键(Key),就可以存取文件了。
这意味着文件之间并不存在关联(树型结构是文件之间的一种关联),可以通过某种算法将文件元信息分散到不同的机器上。
那么为什么文件型存储,不必考虑文件之间的关联?因为关系都在数据库里面,文件型存储只需要负责文件内容的存储,有个键(Key)能够找到文件内容即可。
从本质上来说,这是因为服务端和桌面软件面临的用户场景是完全不同的。文件系统是在桌面软件下的产物,桌面系统是单用户使用的,没有那么高的并发访问需求。
服务端一上来就面临着并发访问的问题,所以很早就出现了数据库这样的存储中间件。数据库的出现,其实已经证明文件系统并不适合服务端。只不过因为文件型存储在早期的服务端开发的比重并不大,所以没有被重视。
但是,互联网的发展极大地加速了文件型存储的发展。互联网增加的 90% 以上的数据,都是非结构化数据,包括图片、音频、视频、日志。
对象存储能够支撑的文件数量规模上非常非常大。比如七牛云存储,我们已经支持万亿级别的文件。
这在传统 NAS 这种基于文件系统访问接口的存储是难以想象的,我们看到的 NAS 存储 POC 测试要求,基本上都是要能够支持 1-2 亿级别的文件存储规模。
另外,对象存储的高速发展,很大程度上会逐步侵蚀 Hadoop 生态的市场。因为 HDFS 这种日志型存储,其实只是对象存储里面的一个特例。在人们习惯了对象存储后,他们并不希望需要学习太多的存储系统;所以大数据的整个生态会逐步过渡到以对象存储为基石。
这已经发生了。这两年你可能也能够听到,Hadoop 生态的公司活得挺不好的,几家公司合并了也没有解决掉没落的问题。这和大数据生态向对象存储迁徙是分不开的,只不过这方面我们国内还处在相对比较落后的阶段。
案例分析
通过对打造“互联网”和存储新兵“对象存储”这两个案例的分析,我们可以看出不同市场差异还是很大的。“互联网” 这个产品它并不是替换某种既有的方案,而是把既有的方案连接在一起。所以 “互联网” 的历史包袱很少,基本上不太需要考虑历史问题。
“对象存储” 产品则不同。在对象存储之前,存储已经经历了很长时间的发展。只不过因为文件型的数据爆发式的增长,带来了存储系统的新挑战,从而给对象存储这样的新技术一个市场机会。
当然,另外一个原因是云服务的诞生,让存储有了新的交付形态。我们不再需要拿着硬件往用户家里搬,这就出现了一个新的空白市场。
但是解决了空白市场的需求后,对象存储还是要面临 “既有市场中用户采用的老存储方案怎么搬迁” 的问题。所以存储网关这样的产品就出现了。存储网关做什么?简单说,就是把对象存储包装成 NAS,提供 NFS、FTP、Samba(CIFS)、WebDAV 这些访问接口给用户使用。
结语
需求分析相关的讨论就到此结束了。不同市场差异非常大,并不存在大一统的产品定义和市场策略,需要具体问题具体分析。
如果你对今天的内容有什么思考与解读,欢迎给我留言,我们一起讨论。下一讲将是我们第一章的回顾与总结。
如果你觉得有所收获,也欢迎把文章分享给你的朋友。感谢你的收听,我们下期再见。