07 CAS:比肩而立的原子魔法
CAS 是 “Compare and Swap”(比较并交换)的缩写,是一种多线程编程中用来实现同步操作的技术。CAS 操作通常用于解决多线程并发访问中,在共享数据时的竞态条件问题。
在 Java 中, CAS 操作主要通过 java.util.concurrent.atomic 包中的原子类来实现,比如AtomicInteger、AtomicLong、AtomicReference等。
CAS 操作的基本思想是,比较数据的当前值与期望值是否相等,如果相同,则正式更新数据。这个比较和修改操作是一个原子操作,因此它可以确保在多线程环境下,只有一个线程能够成功地进行更新操作,避免了竞态条件。如果比较失败(即当前值与期望值不相等),CAS 操作会返回失败,此时可以选择重试或者采取其他策略来处理。
让我们一起回顾一下出现并发安全问题的条件:出现竞态条件和无规则地修改临界区。我们既然在解决并发问题,那么竞态条件就无法避免,因此我们需要着重解决“无规则地修改临界区”这个问题。前面我们介绍的锁机制用于解决这个问题,但在对性能要求非常高的场景下,锁有时显得性能不足,这时我们需要一种无锁化的模式来提高程序性能。
本章节我们将对 CAS,包括使用 CAS 原理做的一些工具类,做一个详细的介绍。
一、CAS 的优劣
总体来讲,CAS 的优势有如下:
- 高效性:CAS 操作是硬件级别的原子操作无需加锁,因此通常比传统的锁机制(如 synchronized)更高效。在高并发场景下,CAS 可以提供更好的性能。
- 避免死锁:CAS 不会导致死锁,因为它不需要获得锁来执行操作。这有助于减少多线程编程中的潜在问题。
- 高并发性:CAS 允许多个线程同时尝试更新同一个内存位置,只有一个线程会成功,其他线程可以根据需要进行重试或采取其他操作。
- 原子性:CAS 操作是原子的,要么成功,要么失败,不会出现中间状态。
人无完人,CAS 也一样,它也是有劣势的,如下:
- 自旋次数限制:CAS 操作如果一直失败,可能导致线程不断自旋,浪费 CPU 资源。因此,需要谨慎设置自旋次数的上限,以避免性能问题。
- ABA 问题:CAS 只关心值的比较,不关心值的变化过程,因此,如果一个值在 CAS 之前和之后都变成了期望值,CAS 无法察觉到这种情况,可能会导致潜在的问题。为了解决 ABA 问题,可以使用带有版本号的 CAS 操作。
二、CAS 的原理
CAS 的原理是基于硬件提供的原子性操作,通常涉及到特定的 CPU 指令。CAS 操作是一种乐观锁机制,它用于解决多线程并发访问共享数据时的竞态条件问题。
下面我们简单分析一下 CAS 的原理。
读取操作:CAS 操作首先读取内存位置的当前值,这是基于硬件提供的原子性操作。这个值将被用于后续比较和更新步骤。比较操作:CAS 会将读取的当前值与预期值(也称为期望值)进行比较。如果当前值等于预期值,则说明没有其他线程在读取或修改这个内存位置的数据,此时 CAS 操作可以继续执行。更新操作:如果比较操作成功(当前值等于预期值),CAS 会使用新值来更新内存位置的内容。这个更新操作是原子的,操作系统确保了不会存在多个线程同时修改这个内存位置的值。失败和重试:如果比较操作失败(当前值不等于预期值),CAS 会返回一个失败标志,表明其他线程已经修改了内存位置的值。在这种情况下,通常需要根据应用的需要来决定如何处理失败,可以选择重试 CAS 操作,或者采取其他策略来解决竞态条件问题。
CAS 操作是原子的,要么成功,要么失败,不会出现中间状态。它不需要显式地加锁,因为硬件确保了 CAS 操作的原子性。这使得 CAS 操作在高并发场景中非常有用,因为多个线程可以同时尝试执行 CAS 操作,只有一个线程会成功,其他线程需要重试或采取其他操作。
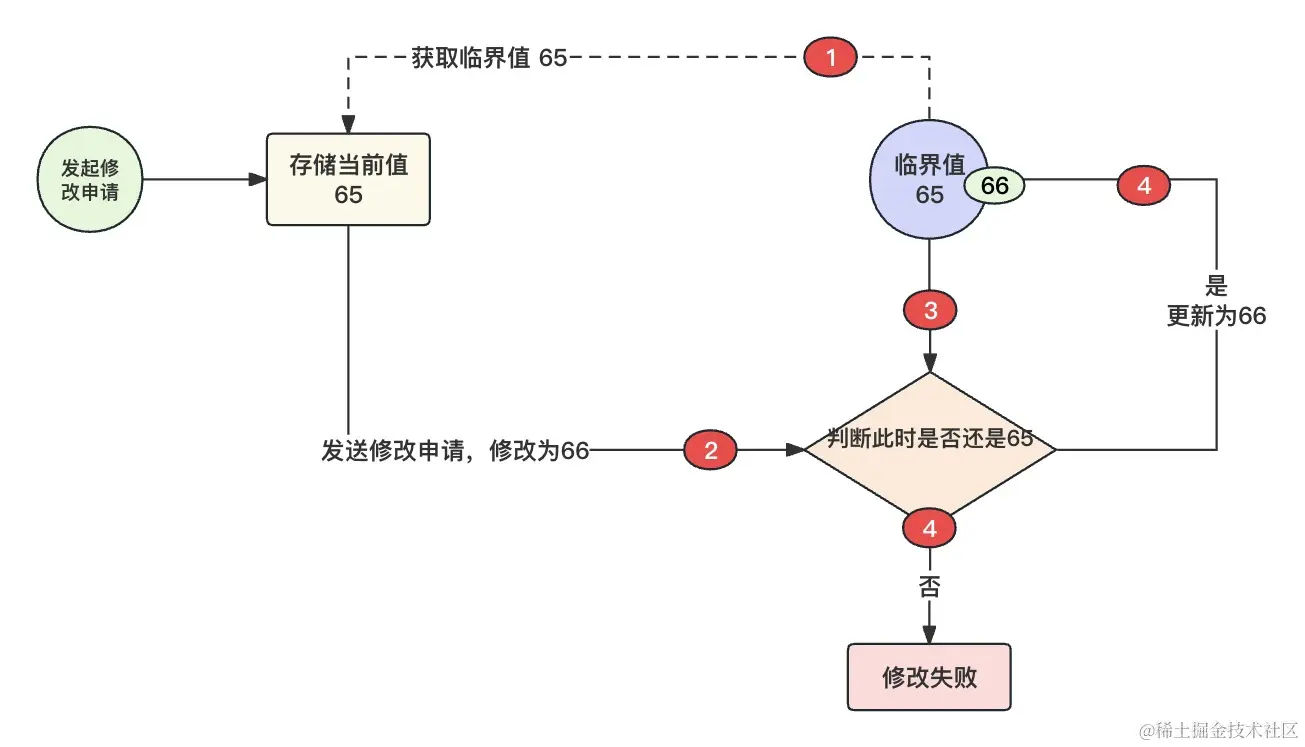
上图是一个简单的 CAS 流程,注意里面的比较、修改操作都是借助于操作系统来进行的(原子操作)。在 Java 中,JVM 虽然无法直接修改操作系统,但是 Java 可以借助于 Unsafe 来进行操作,Unsafe 工具类可以直接操作 JVM 之外的内存。在 NIO 中,所谓的堆外内存,其实也是基于 Unsafe 来进行操作的。关于 Unsafe 的学习,大家可以查阅资料学习,本章节不做太多讲解。
三、CAS 的应用
AtomicXXXX 是 JDK 为我们提供的一组原子工具类,其中主要运用的原理就是 CAS 操作,后续我们将对 JDK 目前常用的 Atomic 原子类做一个具体的学习。
1. AtomicInteger
AtomicInteger 是一个应用于 int 值进行加减操作的原子类,一般实际开发场景中用于计数器的实现,主要 API 如下:
- incrementAndGet:对当前值累加 1 后返回。
- getAndIncrement:返回当前值后,对当前值加 1。
- getAndAdd:返回当前值,并对数据累加一个自定义的数值,减法可以传递负值。
- addAndGet:累加一个自定义的数值,减法可以传递负值,然后返回操作后的值。
- decrementAndGet:对当前变量减 1 后返回数据。
- getAndDecrement:返回当前数据,然后对当前数据减 1。
- compareAndSet(int expect, int update):如果是期望值,则改成要修改的值。比如
expect=1 update =2,当程序发现当前的累加值是 1 的话,就将当前的累加值变为 2;如果不是 1 则不修改;返回值为是否修改成功。
在了解了 AtomicInteger 的 API 的作用后,我们针对累加操作做一个具体的演示,使用两个线程针对一个数据进行累加操作:
public class AtomicIntegerTest {
protected static AtomicInteger atomicInteger = new AtomicInteger();
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new Task());
Thread thread1 = new Thread(new Task());
thread.start();
thread1.start();
thread.join();
thread1.join();
System.out.println(atomicInteger.get());
}
private static class Task implements Runnable {
@Override
public void run() {
for (int i = 0; i < 100000; i++) {
//累加并返回
atomicInteger.incrementAndGet();
}
}
}
}
在 JDK 提供的工具包中,AtomicInteger、 AtomicLong 的用法很相似,所以针对于 AtomicLong 这里不做过多的演示,你可自行探索。
2. AtomicBoolean
AtomicBoolean 主要用于多线程环境下条件的判断,内部只存在 true 和 false 两个值。
我在工作中遇到过这样一个场景:某个 Socket 服务在启动的时候只能启动一次,可以使用 AtomicBoolean 来避免一个服务重复启动两次的场景。
我们使用这个场景来编写一个案例:
public class AtomicBooleanTest {
protected static AtomicBoolean atomicBoolean = new AtomicBoolean(false);
public static void main(String[] args) {
new Thread(new Task()).start();
new Thread(new Task()).start();
new Thread(new Task()).start();
new Thread(new Task()).start();
}
private static class Task implements Runnable {
@Override
public void run() {
if (atomicBoolean.compareAndSet(false, true)) {
System.out.println(Thread.currentThread().getName() + "开始启动服务");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "启动服务占用8080端口");
}else {
System.out.println(Thread.currentThread().getName() + "服务已经被启动了,无须在再次启动");
}
}
}
}
结果如下:
Thread-0开始启动服务
Thread-2服务已经被启动了,无须在再次启动
Thread-1服务已经被启动了,无须在再次启动
Thread-3服务已经被启动了,无须在再次启动
Thread-0启动服务占用8080端口
3. AtomicReference
AtomicReference 与 AtomicInteger、 AtomicLong、 AtomicBoolean 的功能基本一致,我们在日常开发过程中不可能只有数值类型的参数,而 AtomicReference 是可以对引用类型的对象提供原子性的操作。它允许多线程安全地更新引用对象,避免竞态条件问题。
注意:AtomicReference本身可以用于确保引用的原子性操作,但它不会保证引用对象中的属性的线程安全。AtomicReference只能保证引用的替换、获取等操作是原子的,但不会处理引用对象内部状态的线程安全性。
AtomicReference 的用法实际上与 AtomicBoolean 十分相似,我们还是先介绍主要的 API。
AtomicReference<V>():无参构造函数,创建一个初始引用值为null对象。AtomicReference<V>(V initialValue):可以传递一个希望变为原子引用的对象。V get():获取当前原子对象的值。void set(V newValue):设置当前原子对象的值。V getAndSet(V newValue):先获取旧的原子值,再将新的设置到 AtomicReference 中。boolean compareAndSet(V expect, V update):比较当前对象中的引用值与期望值(expect)是否相等,如果相等,则将对象中引用的值更新为新值(update),返回true表示更新成功,否则返回false表示更新失败。这是一个常用的原子操作,用于实现乐观锁的模式。
我们尝试使用一个简单的案例来说明它的使用方法,使用 compareAndSet 来进行比对,如果数据等于预期值则更新,否则不更新:
public class AtomicReferenceTest {
public static void main(String[] args) {
AtomicReference<String> atomicReference = new AtomicReference<>();
//设置一个值
atomicReference.set("abcd");
//获取一个值
System.out.println(atomicReference.get());
//比较后更新
System.out.println(atomicReference.compareAndSet("abcd", "hf"));
//获取值
System.out.println(atomicReference.get());
}
}
我们还可以尝试 AtomicReference 来实现一个自旋锁的操作。
想法是这样的:加锁的时候使用 AtomicReference 判断是否为空,为空就将当前线程设置进去,同时加锁成功;解锁的时候判断 AtomicReference 中是否是当前的线程,如果是,当前的线程则设置为 null,同时解锁成功。
public class SpinLockDemo {
private AtomicReference<Thread> atomicReference = new AtomicReference<>();
/**
* 加锁操作
*/
public void lock(){
//获取当前线程
Thread thread = Thread.currentThread();
//判断 是不是有线程持有锁,如果锁为空,则将当前线程分配锁!否则自旋
while (!atomicReference.compareAndSet(null, thread)) {
System.out.println(Thread.currentThread().getName() + "尝试重新获取锁");
}
}
/**
* 解锁操作
*/
public void unLock(){
//获取当前线程
Thread thread = Thread.currentThread();
//如果是当前线程 就将当前线程设为null 解锁
atomicReference.compareAndSet(thread, null);
}
public static void main(String[] args) throws InterruptedException {
Task task = new Task(new SpinLockDemo());
Thread thread1 = new Thread(task,"线程1");
Thread thread2 = new Thread(task,"线程2");
Thread thread3 = new Thread(task,"线程3");
thread1.start();
thread2.start();
thread3.start();
thread1.join();
thread2.join();
thread3.join();
System.out.println("此时值为:" + task.i);
}
private static class Task implements Runnable{
int i = 0;
private final SpinLockDemo spinLockDemo;
private Task(SpinLockDemo spinLockDemo) {
this.spinLockDemo = spinLockDemo;
}
@Override
public void run() {
spinLockDemo.lock();
try {
for (int j = 0; j < 100000; j++) {
i++;
}
}finally {
spinLockDemo.unLock();
}
}
}
}
我们看最终的结果,也是能够保证线程安全的:
线程1获取到锁
线程3尝试重新获取锁
线程2尝试重新获取锁
线程2尝试重新获取锁
线程2尝试重新获取锁
线程2获取到锁
线程3尝试重新获取锁
线程3尝试重新获取锁
线程3获取到锁
此时值为:300000
4. AtomicXXXArray
AtomicXXXArray 包括 AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray,它是一个原子数组,在该类的原子数组都能够实现线程安全的原子操作。
我们首先了解一下它的主要 API。
AtomicIntegerArray(int length):构造函数,创建一个包含指定长度的AtomicIntegerArray,并初始化所有元素为 0。AtomicIntegerArray(int[] array):构造函数,创建一个包含与给定整数数组相同长度的AtomicIntegerArray,并将其初始化为与给定数组相同的值。get(int index):获取指定索引位置的元素的值,返回一个普通的整数值,不具备原子性。set(int index, int newValue):将指定索引位置的元素设置为新的值,这个操作是原子性的。getAndSet(int index, int newValue):获取指定索引位置的元素的当前值,并将其设置为新的值,返回的是设置之前的值。compareAndSet(int index, int expect, int update):比较指定索引位置的元素的当前值与期望值(expect),如果相等,将该元素的值更新为新值(update),返回true表示更新成功,false表示更新失败。getAndIncrement(int index):获取指定索引位置的元素的当前值,并将其自增,返回的是自增前的值。getAndDecrement(int index):获取指定索引位置的元素的当前值,并将其自减,返回的是自减前的值。getAndAdd(int index, int delta):获取指定索引位置的元素的当前值,并将其加上指定的增量(delta),返回的是加操作前的值。incrementAndGet(int index):自增指定索引位置的元素的值,并返回自增后的值。decrementAndGet(int index):自减指定索引位置的元素的值,并返回自减后的值。addAndGet(int index, int delta):将指定索引位置的元素加上指定的增量(delta),并返回加操作后的值。
我们使用 AtomicIntegerArray 来做演示,这里我们还是以一个案例为切入点去学习它的使用。
假设有这样一个场景,我们有 20 组线程,每一组线程都有两个线程 A 和 B,A 线程对数组内所有的值 +1,线程 B 对数组内所有的值 -1。那么我们最终等待线程运行完毕之后,尝试获取数组内的元素,在线程安全的情况下,此时数组内的数据应该全部都为 0。
public class AtomicIntegerArrayTest {
public static void main(String[] args) throws InterruptedException {
AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(1000);
List<Thread> threadList = new ArrayList<>(40);
IncrementTask task1 = new IncrementTask(atomicIntegerArray);
DecrementTask task2 = new DecrementTask(atomicIntegerArray);
for (int i = 0; i < 20; i++) {
Thread thread1 = new Thread(task1);
Thread thread2 = new Thread(task2);
thread1.start();
thread2.start();
threadList.add(thread1);
threadList.add(thread2);
}
//等待线程结束
for (Thread thread : threadList) {
thread.join();
}
System.out.println("线程执行完毕");
//获取当前原子数组中的数据
for (int i = 0; i < atomicIntegerArray.length(); i++) {
System.out.println(atomicIntegerArray.get(i));
}
}
/**
* 进行累加操作
*/
private static class IncrementTask implements Runnable {
private final AtomicIntegerArray atomicIntegerArray;
private IncrementTask(AtomicIntegerArray atomicIntegerArray) {
this.atomicIntegerArray = atomicIntegerArray;
}
@Override
public void run() {
for (int i = 0; i < atomicIntegerArray.length(); i++) {
//对i位置进行+1操作
atomicIntegerArray.incrementAndGet(i);
}
}
}
/**
* 进行递减操作
*/
private static class DecrementTask implements Runnable {
private final AtomicIntegerArray atomicIntegerArray;
private DecrementTask(AtomicIntegerArray atomicIntegerArray) {
this.atomicIntegerArray = atomicIntegerArray;
}
@Override
public void run() {
for (int i = 0; i < atomicIntegerArray.length(); i++) {
//对i位置进行-1操作
atomicIntegerArray.decrementAndGet(i);
}
}
}
}
最终结果数组内的数据还是全部为 0,有关 AtomicLongArray、AtomicReferenceArray 的使用不再做重复讲解,基本一致。
5. AtomicXXXFieldUpdater
AtomicXXXFieldUpdater 存在 AtomicReferenceFieldUpdater、AtomicIntegerFieldUpdater、AtomicLongFieldUpdater 三种实现方式。
AtomicXXXFieldUpdater 的意义是它用于原子性地更新对象中的某个字段,而不需要使用锁来保护字段的更新操作。这个类允许你在多线程环境中高效地进行对象字段的原子更新。
我们前面讲过的 AtomicReference 虽然也是针对对象的原子操作,但是它只能保证自身而无法保证自身内的属性的原子操作,AtomicXXXFieldUpdater 就可以实现将某一个对象内的属性变为原子操作。
我们以 AtomicIntegerFieldUpdater 为例,它用于更新一个对象中 int 属性的值进行加减操作,具体如下:
public class AtomicIntegerFieldUpdaterTest {
public static void main(String[] args) throws InterruptedException {
AtomicIntegerFieldUpdater<Count> atomicIntegerFieldUpdater = AtomicIntegerFieldUpdater.newUpdater(Count.class, "count");
Count count = new Count();
Task task = new Task(count, atomicIntegerFieldUpdater);
Thread thread = new Thread(task);
Thread thread1 = new Thread(task);
thread.start();
thread1.start();
thread.join();
thread1.join();
System.out.println(count.count);
}
private static class Task implements Runnable {
private final Count count;
private final AtomicIntegerFieldUpdater atomicIntegerFieldUpdater;
private Task(Count count, AtomicIntegerFieldUpdater atomicIntegerFieldUpdater) {
this.count = count;
this.atomicIntegerFieldUpdater = atomicIntegerFieldUpdater;
}
@Override
public void run() {
for (int i = 0; i < 100000; i++) {
//对对象内的数据进行累加操作
atomicIntegerFieldUpdater.incrementAndGet(count);
}
}
}
private static class Count {
volatile int count;
}
}
我们再来看下 AtomicReferenceFieldUpdater 的使用,它用于更新对象中普通属性的原子修改:
public class AtomicReferenceFieldUpdaterTest {
public static void main(String[] args) throws InterruptedException {
AtomicReferenceFieldUpdater<Log, String> atomicReferenceFieldUpdater = AtomicReferenceFieldUpdater.newUpdater(Log.class, String.class, "logMessage");
Log log = new Log("a");
if (atomicReferenceFieldUpdater.compareAndSet(log,"a", "b")) {
System.out.println("原子更新成功");
}
System.out.println(log.logMessage);
}
private static class Log {
volatile String logMessage;
public Log(String logMessage) {
this.logMessage = logMessage;
}
}
}
在使用 AtomicXXXFieldUpdater 的时候,被升级的属性需要有以下几个注意点:
- 被修改的属性必须要声明为 volatile,否则会抛出
Must be volatile type异常。 - 要升级的原子属性是不允许被声明为 static 的,否则会抛出
java.lang.IllegalArgumentException异常。
6. AtomicXXX 的原理图示
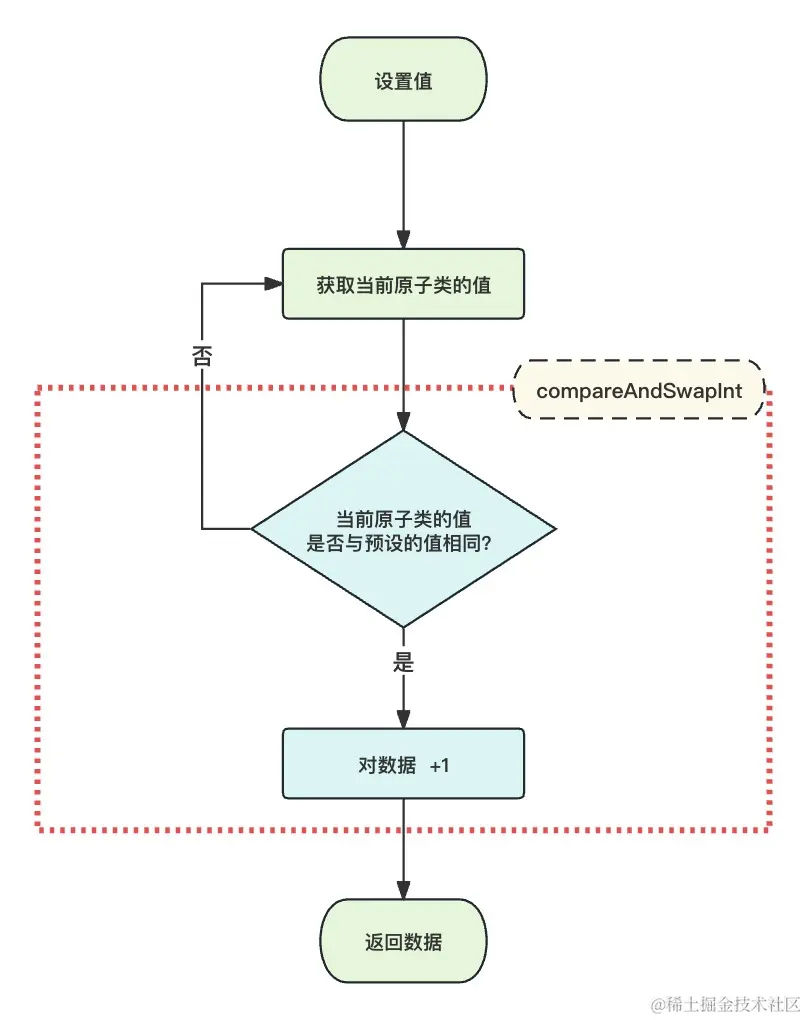
上文一直在说它是基于 CAS 加上自旋来实现的,本节我们将对它的实现机理给出说明。
以 AtomicInteger 为例,看一下它累加的源码,做一个简单的分析:
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);
} while (!compareAndSwapInt(o, offset, v, v + delta));
return v;
}
可以很清楚地看到,它的实现方式是自旋的方式,compareAndSwapInt 方法是一个 native 方法,直接由 C++ 代码实现,它的意义就是对比、然后设置,如果没有设置上,就返回 false,直到自旋设置成功为止!
画一张图展示下:
7. Adder 累计器
在之前的学习中,我们了解了 AtomicInteger,它是用于原子性地操作整数值的工具类。类似地,AtomicLong 用于原子性操作长整数值,主要用于累加操作。
现在,让我们介绍一种新的工具类,即 LongAdder,它在 Java 8 中引入,旨在优化替代 AtomicLong。虽然原子类提供了便捷的原子操作,但它们使用自旋锁的方式来实现,这在极端情况下可能导致某一个线程会频繁地对比失败无法设置新值进而自旋,导致性能的整体下降。
LongAdder 是为了解决这个性能问题而设计的。它采用一种 分段锁 的策略,将累加操作分散到多个单元(称为“单元”或“分段”),从而减少了竞争。这使得在高度并发的情况下,LongAdder 能够提供更好的性能,避免了单一锁的瓶颈。
因此,LongAdder 是一个更适合在高并发环境下执行长整数累加操作的工具类,可以显著提高性能并减轻潜在的竞态条件问题。
它的主要原理其实是采用“分而治之”的思想。
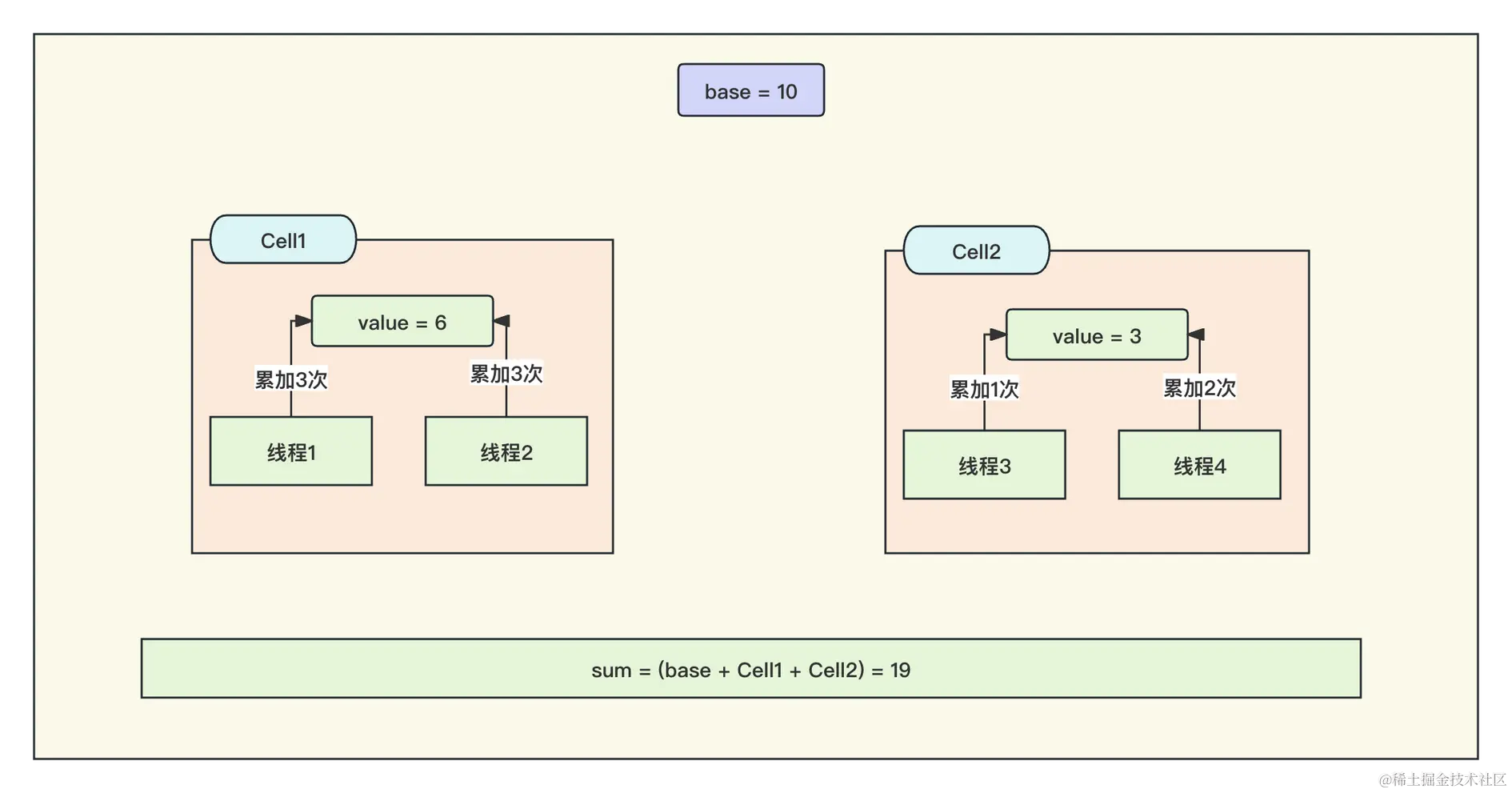
我们在上文分析过 Atomic 的累加方式,它是一条线程不断地去验证是否等于更新前的值,每一个线程都在自旋等待更改这个值。而 LongAdder 是根据竞争的线程数衍生出了一个 Cell 数组,每一个 Cell 都维护几个线程的累加,最终获取值的时候将所有 Cell 的累加值加上初始值,就等于最终的结果。
我们可以总结一下这个过程:
- 分段累加:
LongAdder使用分段锁的方式来实现累加操作。多个线程可以同时累加,因为它们会选择不同的Cell,而不会争夺同一个锁。这减少了竞争和锁争用,提高了性能。 - 局部累加: 每个
Cell维护一个局部累加值,线程进行累加操作时,会选择一个Cell并在该Cell上进行操作。这减少了对共享资源的访问,因为每个线程只操作自己选择的Cell。 - 合并操作: 当需要获取累加结果时,
LongAdder会将所有Cell的局部累加值与base的值相加,以计算出最终的累加结果。这个合并操作是原子的。
我们看一下具体用法:
public class LongAdderTest {
protected static LongAdder longAdder = new LongAdder();
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new Task());
Thread thread1 = new Thread(new Task());
thread.start();
thread1.start();
thread.join();
thread1.join();
System.out.println(longAdder.sum());
}
private static class Task implements Runnable {
@Override
public void run() {
for (int i = 0; i < 100000; i++) {
//累加并返回
longAdder.increment();
}
}
}
}
可以看到,我们获取最终的累加结果的时候,采用的是 longAdder.sum 来获取的。我们可以简单分析下 sum 方法,这样你会理解得更为透彻:
public long sum() {
Cell[] as = cells; Cell a;
//base值
long sum = base;
if (as != null) {
//循环Cell 进行累加操作
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
可以看到,事实上内部做了一个循环,将 base 的值和 Cell 数组中每一个 Cell 的值累加起来,得到最终的结果。
注意:longAdder 使用的场景是统计求和,而且适用于并发场景特别高的情况下;如果并发数量不大的话,事实上它与 Atomic 的效率也差不多。
8. LongAccumulator
我们在生产环境中面对的需求是复杂多样化的,有时候我们的需求可能不止是累加操作,比如要求乘法等问题,LongAccumulator 就是为了解决这个问题。
LongAccumulator 是 Java 中用于累加长整数值的类,它也是 Java 8 引入的。与 LongAdder 类似,LongAccumulator 用于在高并发环境中执行长整数的累加操作。但与 LongAdder 不同,LongAccumulator 具有更高的灵活性,允许你自定义累加操作。
LongAccumulator 的核心是一个长整数值,以及一个用户定义的二元操作函数(BinaryOperator),这个函数用于指定如何对长整数值进行累加。累加操作是原子的,并且支持多线程并发累加。
我们看一下它的用法:
public class LongAccumulatorTest {
public static void main(String[] args) {
LongAccumulator longAccumulator = new LongAccumulator((x,y)-> x * y, 1);
longAccumulator.accumulate(1);
longAccumulator.accumulate(2);
longAccumulator.accumulate(3);
System.out.println(longAccumulator.getThenReset());
}
}
想要理解 LongAccumulator 的执行逻辑,就必须要理解 LongAccumulator 初始化的时候传入的回调类,它的过程是:
- 第一次运算的时候,将初始化传递的 1 当作 x 值,将 accumulate(1),做计算。
- 将第一次计算的结果当做 x 值,将 accumulate(2) 当作 y 值计算。
- 以此类推,最终的计算为 1 x 1 x 2 x 3 = 6。
LongAccumulator 的意义是灵活,它的计算逻辑完全由使用者自己编写,而且使用这个类还可以在多线程并发的情况下保证最终结果的正确性!它适用于大量计算且并行的场景!注意并发情况下,线程的执行顺序是不确定的,所以 LongAccumulator 只适合执行顺序不影响最终结果的场景!
四、总结
我们本章节剖析了 CAS 的基本原理,介绍了 JDK 内部对于 CAS 的实现方式即原子类,它可以保证一些操作被“不可分割”地执行,保证了线程安全。同时,还分享了 7 种类型的 JDK 对于原子类的实现!
相信经过本章节的学习,你会对 CAS 的原理以及 JDK 中对于 CAS 原理的实现有了一个更加清晰的认知。